1 基础概念
Elasticsearch是一个近实时的系统,从你写入数据到数据可以被检索到,一般会有1秒钟的延时。Elasticsearch是基于Lucene的,Lucene的读写是两个分开的句柄,往写句柄写入的数据刷新之后,读句柄重新打开,这才能读到新写入的数据。
名词解释:
Cluster:集群。
Index:索引,Index相当于关系型数据库的DataBase。
Type:类型,这是索引下的逻辑划分,一般把有共性的文档放到一个类型里面,相当于关系型数据库的table。
Document:文档,Json结构,这点跟MongoDB差不多。
Shard、Replica:分片,副本。
分片有两个好处,一个是可以水平扩展,另一个是可以并发提高性能。在网络环境下,可能会有各种导致分片无法正常工作的问题,所以需要有失败预案。ES支持把分片拷贝出一份或者多份,称为副本分片,简称副本。副本有两个好处,一个是实现高可用(HA,High Availability),另一个是利用副本提高并发检索性能。
分片和副本的数量可以在创建index的时候指定,index创建之后,只能修改副本数量,不能修改分片。
健康状态:
安装了head插件之后,可以在web上看到集群健康状态,集群处于绿色表示当前一切正常,集群处于黄色表示当前有些副本不正常,集群处于红色表示部分数据无法正常提供。绿色和黄色状态下,集群都是能提供完整数据的,红色状态下集群提供的数据是有缺失的。
2 搭建ElasticSearch
首先安装java,设置好JAVA_HOME环境变量(export JAVA_HOME=.../java8),然后安装Elasticsearch。
参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html
设置配置的时候,ES可能因为各种原因不能自动找到集群,所以把地址也设置上,如:
discovery.zen.ping.unicast.hosts: ["host_name...:9301", "host_name_xxx:port_yyy"...]
安装head插件:拉取 https://github.com/mobz/elasticsearch-head 代码,将其放到./plugins/head 目录下。
启动之前设置ES使用的内存:export ES_HEAP_SIZE=10g。
elasticsearcy.yml配置文件中的一些配置点:
#设置集群名字 cluster.name: cswuyg_qa_pair_test#设置node名字 node.name: xxx-node#设置节点域名 network.host: 10.111.111.1#设置内部传输端口和外部HTTP访问端口 transport.tcp.port: 9302 http.port: 8302#设置集群其它节点地址 discovery.zen.ping.unicast.hosts: ["xxxhost:yyyport"]#设置中文切词插件 index.analysis.analyzer.ik.type: "ik"
elasticsearch -d 以守护进程方式启动,启动之后,就可以在浏览器里使用head插件看到集群信息,如:
http://host_name_xxx:port_yyy/_plugin/head/
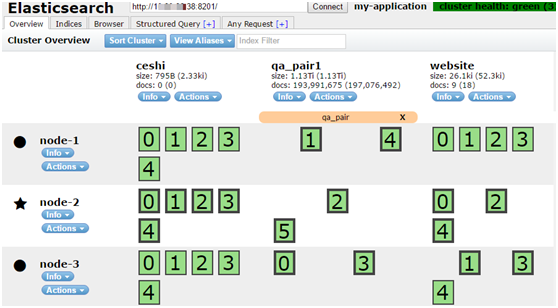
上图:启动了三个Elasticsearch实例,创建了三个Index;ceshi Index有一主shard,两replica shard;qa_pair1 Index只有主shard;website Index有一主shard,一replica shard。
3 测试Elasticsearch使用
Elasticsearch提供RESTful API,我采用Postman(chrome的一个插件)作为辅助客户端向ES发送请求。
可以向任意一个节点发起请求,虽然ES有Master的概念,但任意一个node都可以接受读写请求。
先创建一个index:
POST http://10.11.111.11:8301/test_index
查看创建的index:
GET http://10.11.111.11:8301/_cat/indices?v
写入数据:

查询数据:
(1)使用id直接查:
GET http://xxxhost:8201/qa_xx2/qa_xx3/1235(2)DSL查询:往查询url POST数据即可:
URL格式:http://xxxhost:8201/qa_xx2/qa_xx3/_searcha. 查询title中包含有cswuyg字段的文档。Highlight设置高亮命中的词。POST方法的body:

{ "query": { "match": { "title": { "query": "cswuyg " } } }, "highlight": { "fields": { "title": { } } } } b. bool组合查询,命中的文档的title字段必须能命中“餐厅”、“好吃”、“深圳”,可以是完全命中,也可以是名字其中的个别字。“便宜”则是可选命中。
POST方法的body: { "query": { "bool": { "must": [{ "match": { "title": { "query": "餐厅" } } }, { "match": { "title": { "query": "好吃" } } }, { "match": { "title": { "query": "深圳" } } }], "should": [{ "match": { "title": "便宜" } }] } }, "highlight": { "fields": { "title": { } } } } 如果要求每一个字都命中,可以把match修改为match_phrase。
{ 'query': { 'bool': { 'should': [{ 'match': { 'title': { 'query': '张三', 'boost': 0.2 } } }], 'must': [{ 'match_phrase': { 'title': { 'query': '李四', 'boost': 0.69 } } }, { 'match_phrase': { 'title': { 'query': '王五', 'boost': 0.11 } } }] } } } 例子:要求必须完全命中“酒后”和“标准",“驾驶”可以部分命中
{ "query": { "bool": { "must": [{ "match_phrase": { "question": { "query": "酒后", "boost": 0.69 } } }, { "match": { "question": { "query": "驾驶", "boost": 0.11 } } }, { "match_phrase": { "question": { "query": "标准", "boost": 0.2 } } }] } } } c. 给查询词设置权重(boost)。POST方法的body:
{ "query": { "bool": { "must": { "match": { "title": { "query": "好吃的餐厅", "boost": 1 } } }, "must": { "match": { "title": { "query": "深圳湾", "boost": 100 } } }, "should": [{ "match": { "title": "便宜" } }] } }, "highlight": { "fields": { "title": { } } } } d. filter查询,也就是kv查询,不涉及检索的相关性打分,title必须是完全命中,如果建库时是有对这个字段切词的,则查询时,需要是切词后的某个词去查询,如“今天天气”,建库切词为“今天”和“天气”,那么filter查询的时候需要使用“今天”或者“天气”才能命中。POST方法的body:
{ "query": { "bool": { "filter": [{ "term": { "title": "好吃的" } }] } } } e. 完全匹配某个短语,这就要求“好厉害”三个字组成的词必须在文档中出现,不能是只出现其中的个别字(match就是这样)。POST方法的body:
{ "query": { "match_phrase": { "title": { "query": "好厉害" } } }} (3)运维
a. 去掉副本,调研的时候希望不要副本,这样子写入会快点
PUT http://10.11.111.11:8202/qa_pair2/_settings{ "number_of_replicas" : 0} 4 使用ik中文切词插件
Elasticsearch默认的中文切词插件是单字切词,这不能满足我们要求,需要安装中文切词插件。
插件github地址:https://github.com/medcl/elasticsearch-analysis-ik
源码安装:编译时需要联网,可以在windows下编译完之后,把elasticsearch-analysis-ik-1.9.3.zip拷贝到linux机器的./plugin/head目录下解压。配置:在配置文件./config/elasticsearch.yml末尾添加配置: index.analysis.analyzer.ik.type: "ik"测试ik切词:http://host_name_xx:port_yyy/qa_pair/_analyze?analyzer=ik&pretty=true&text=我是中国人"